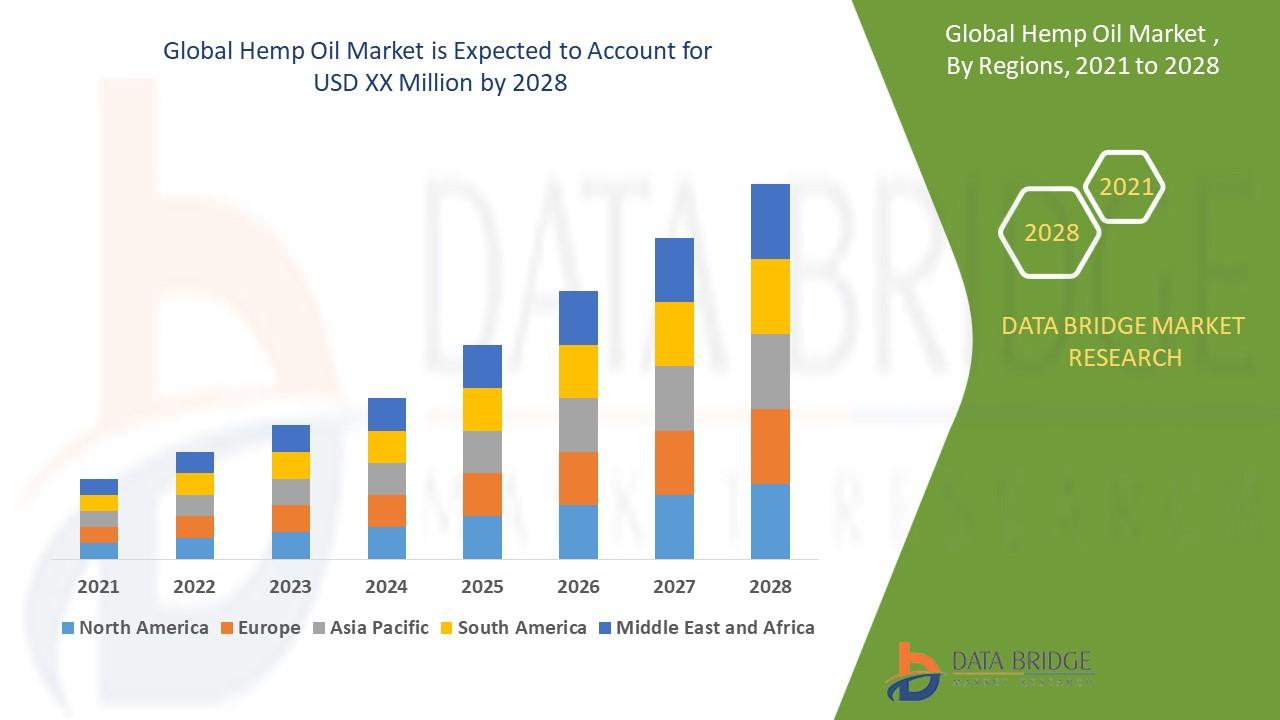
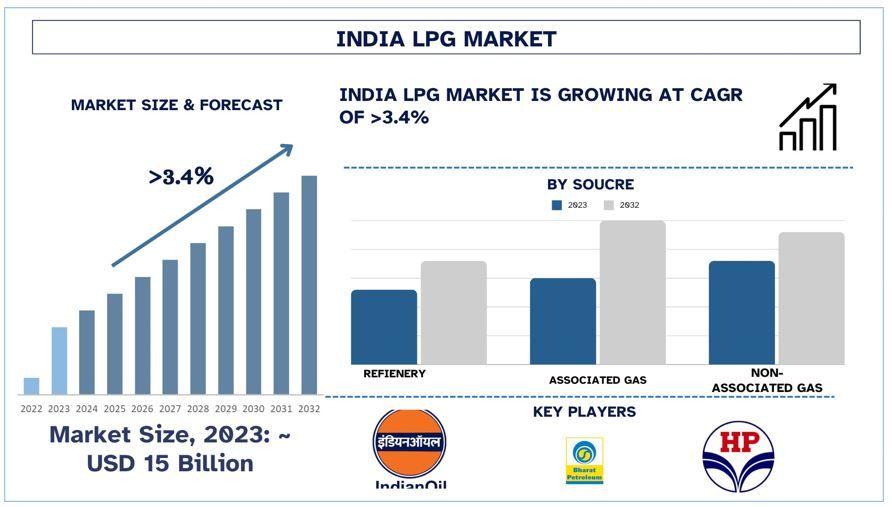
Introduction to Data Cleaning
Every business, organization, and digital platform relies heavily on data to make informed decisions. However, raw data is rarely perfect. It often contains inconsistencies, missing values, duplicate entries, and errors that can compromise analysis. This is where data cleaning becomes essential.
Data cleaning, also known as data cleansing, is the process of identifying and correcting inaccuracies in datasets to improve their quality. Whether you are working in data science, business intelligence, or machine learning, clean data is the foundation for accurate results.
This comprehensive guide explores everything you need to know about data cleaning, including techniques, tools, benefits, and best practices to ensure your datasets are reliable and actionable.
What is Data Cleaning?
Definition of Data Cleaning
The Data cleaning refers to the process of detecting and fixing (or removing) corrupt, incomplete, or irrelevant data within a dataset. The goal is to ensure that data is accurate, consistent, and usable for analysis.
Why is Data Cleaning Important?
Poor-quality data can lead to:
- Incorrect business decisions
- Misleading analytics
- Reduced operational efficiency
- Loss of customer trust
On the other hand, high-quality clean data enables:
- Better data analysis
- Accurate predictive modeling
- Improved data visualization
- Reliable business insights
Common Problems in Raw Data
Understanding the issues in raw datasets is the first step toward effective data cleaning.
1. Missing Data
Missing values are one of the most common issues in data preprocessing. They can occur due to:
- Data entry errors
- System failures
- Incomplete records
2. Duplicate Records
Duplicate entries can distort analysis results and lead to incorrect conclusions.
3. Inconsistent Formatting
Examples include:
- Different date formats
- Mixed units of measurement
- Inconsistent naming conventions
4. Outliers and Errors
Outliers can skew statistical analysis and may result from:
- Measurement errors
- Data entry mistakes
5. Invalid Data
This includes incorrect values such as:
- Negative ages
- Invalid email formats
- Incorrect categorical entries
Key Steps in the Data Cleaning Process
1. Data Inspection
The first step in data cleaning is analyzing the dataset to identify issues. This includes:
- Reviewing data types
- Checking for missing values
- Identifying anomalies
2. Handling Missing Values
Techniques include:
- Removing rows with missing data
- Filling missing values using mean, median, or mode
- Using advanced imputation techniques
3. Removing Duplicates
Duplicate records should be identified and removed to ensure data accuracy.
4. Standardizing Data
Standardization ensures consistency across the dataset, such as:
- Uniform date formats
- Consistent capitalization
- Standard measurement units
5. Fixing Errors
Correcting errors involves:
- Validating data against rules
- Using automated scripts for correction
6. Data Validation
After cleaning, the dataset should be validated to ensure accuracy and completeness.
Popular Techniques for Data Cleaning
Data Filtering
Filtering helps remove irrelevant or unnecessary data points.
Data Transformation
Transforming data into a consistent format improves usability.
Data Normalization
Normalization ensures that data values fall within a specific range, which is crucial for machine learning algorithms.
Outlier Detection
Identifying and handling outliers is essential for maintaining data integrity.
Tools Used for Data Cleaning
Spreadsheet Tools
Tools like Excel are widely used for basic data cleaning tasks, including:
- Sorting
- Filtering
- Removing duplicates
Programming Languages
- Python (Pandas, NumPy)
- R
These tools are ideal for advanced data preprocessing.
Data Cleaning Software
Dedicated tools and platforms simplify the cleaning process. For example, platforms like Sourcetable allow users to manage and clean data efficiently within spreadsheet-like environments.
Data Cleaning in Data Science
Role in Data Science Workflow
In data science, up to 80% of the time is spent on data cleaning and preparation. Clean data ensures:
- Accurate model training
- Reliable predictions
- Improved performance
Impact on Machine Learning
Poor data quality can significantly affect machine learning models, leading to:
- Overfitting
- Underfitting
- Biased results
Clean datasets help models learn patterns more effectively.
Best Practices for Effective Data Cleaning
1. Understand Your Data
Before cleaning, thoroughly analyze the dataset to understand its structure and issues.
2. Create a Data Cleaning Plan
Define clear steps and objectives for the cleaning process.
3. Automate Where Possible
Automation tools can save time and reduce human error.
4. Maintain Data Integrity
Avoid over-cleaning, which can remove valuable information.
5. Document Changes
Keep records of all modifications for transparency and reproducibility.
Challenges in Data Cleaning
Time-Consuming Process
Cleaning large datasets can be labor-intensive and time-consuming.
Data Complexity
Complex datasets with multiple variables require advanced techniques.
Lack of Standardization
Different data sources often follow different formats, making cleaning difficult.
Human Error
Manual cleaning increases the risk of introducing new errors.
Benefits of Data Cleaning
Improved Decision-Making
Clean data leads to more accurate and reliable insights.
Enhanced Data Quality
High-quality data improves overall business performance.
Better Customer Insights
Accurate data helps understand customer behavior more effectively.
Increased Efficiency
Automation and clean datasets streamline workflows.
Real-World Applications of Data Cleaning
Healthcare
In healthcare, clean data ensures accurate patient records and diagnoses.
Finance
Financial institutions rely on clean data for fraud detection and risk analysis.
E-commerce
E-commerce platforms use data cleaning to:
- Improve product listings
- Enhance customer experience
- Optimize pricing strategies
Marketing
Marketers use clean data for targeted campaigns and better ROI.
Advanced Data Cleaning Techniques
Machine Learning-Based Cleaning
AI models can automatically detect and correct data anomalies.
Data Deduplication Algorithms
Advanced algorithms help identify duplicates more efficiently.
Data Profiling
Profiling tools analyze datasets to identify patterns and inconsistencies.
Future of Data Cleaning
The future of data cleaning is evolving with advancements in:
- Artificial Intelligence
- Automation
- Cloud-based data platforms
These innovations are making data cleansing faster, more efficient, and more accurate.
Conclusion
Data cleaning is a critical step in any data-driven process. Without clean data, even the most advanced analytics and machine learning models can produce unreliable results. By implementing effective data cleaning techniques, using the right tools, and following best practices, organizations can unlock the true value of their data.
Investing time and effort into data preprocessing ensures better decision-making, improved efficiency, and long-term success in today’s data-driven world.